
How a Merkl campaign is built: understanding the configuration
Every distribution that runs on Merkl, from a simple reward on a single token to a multi-layered program spanning several lending markets, comes down to the same thing: a campaign configuration.
A configuration is the set of inputs that fully describes a campaign. It says what activity is being rewarded, how the budget is spent over time, how individual contributions are turned into reward shares, who qualifies, and any special handling layered on top.
This article walks through how a configuration is put together. Once the basics are clear, even the most complex programs are just the same parts, combined differently.
What a configuration actually is
Think of a configuration as a recipe. It is a structured list of ingredients that tells the Merkl engine exactly how a campaign should behave. Nothing about a campaign is improvised. Every behavior you see, the target asset, the rate, the eligibility rules, comes from a field in this recipe.
The useful thing to understand first is that a configuration is read on two layers:
- Standard fields are the simple, top-level settings that almost every campaign shares. They hold simple values, such as a wallet or token address, an amount, or a date. Think of them as the frame around the campaign.
- Structured inputs are the richer building blocks. Each one is its own object with its own schema, and each one configures a specific part of how the campaign works.
Let's look at each.
The standard fields: the frame around a campaign
Standard fields are present on most campaigns and take simple values. They define the basic shape of the program: who runs it, what is being paid, how much, where, and when.
creator: the address that owns and manages the campaign.rewardToken: the address of the token being paid out as rewards.amount: the total budget to be distributed.distributionChainId: the chain where rewards are distributed.computeChainId: the chain where user activity is tracked. It can differ from the distribution chain for cross-chain campaigns.startTimestampandendTimestamp: when the campaign starts and ends, as Unix timestamps.blacklist(optional): a list of addresses excluded from receiving rewards.whitelist(optional): a list of addresses allowed to receive rewards. If it is set, everyone else is excluded.
The structured inputs: the building blocks
The standard fields tell Merkl the shape of the campaign. The structured inputs tell it how the campaign actually works. Each is a self-contained object backed by its own schema, a published definition of exactly which fields it accepts, which means each can be as simple or as detailed as the program requires.
Merkl groups them as follows:
| Structured input | What it describes |
|---|---|
| Campaign type | The activity being rewarded and the parameters it accepts |
| Distribution method | How the budget is spent over time |
| Compute-score method | How individual contributions become reward shares |
| Hook type | Boosts and advanced customizations on top of the campaign |
You will rarely touch all of them at once. Simple campaigns lean on the first two. The rest are there when a program needs more precision. Note that not every campaign type works with every distribution method, and some hooks only apply to certain types. Let's take them one at a time.
The campaign type
The campaign type answers the most basic question: what behavior are you rewarding?
Different types reward different activity. Some reward providing liquidity in a concentrated liquidity pool, like Uniswap V3. Others reward lending or borrowing on a protocol such as Morpho. Some reward holding a token over time, like wBTC or ETH. Others distribute a one-off airdrop to many addresses at once. Each type also defines the parameters it expects, which it carries in its own structured object.
This is why the campaign type is a structured input rather than a standard field. The asset you are targeting, for example, lives inside the campaign type's parameters, because what counts as a valid target depends entirely on which type you picked.
If you are exploring what is possible, the list of supported types is published live in the schema explorer.
The distribution method
Once you know what you are rewarding, the distribution method decides how the budget is spent over the life of the campaign.
This is where two very different programs can share the same campaign type but behave in opposite ways. A couple of common approaches:
- A target-APR method tells Merkl to spend whatever it takes to keep the opportunity at a chosen rate. If activity grows, spend goes up. If it shrinks, spend goes down. The rate stays steady.
- A fixed-rewards method spends a set amount over the period, regardless of how much activity shows up. The budget is fixed, the resulting rate floats.
Each method carries its own settings, such as the target rate or whether token pricing is used in the calculation. Choosing a method is really a choice about what you want to hold constant: the rate, or the spend.
The compute-score method
The first two blocks define the campaign at the level of the whole opportunity. The compute-score method works at the level of each individual participant.
Its job is to turn raw activity into shares. Two wallets supplying liquidity in the same pool may have contributed different amounts for different lengths of time. The compute-score method decides how those differences translate into a portion of the rewards. It is the difference between "this pool earned X" and "this specific wallet earned Y."
For most standard campaigns the default scoring does exactly what you would expect, rewarding participants in proportion to their contribution. The method becomes interesting when a program wants to weight things differently.
Hooks and customizations
Hooks are where a campaign gets fine-tuned beyond the basics. They sit on top of everything else and adjust how the distribution behaves.
This is distinct from simple eligibility. Allow lists and deny lists are already handled by the whitelist and blacklist standard fields. Hooks cover the more advanced cases. Common ones include boosting rewards for users who hold a specific token or NFT, or restricting eligibility to addresses that hold a minimum amount of a token over a set period, for example only rewarding wallets that hold at least 500 of a token for 30 days. The full list of available hooks is published in the schema explorer. If a campaign behaves in a way that feels custom, a hook is usually the reason.
What a configuration looks like in practice
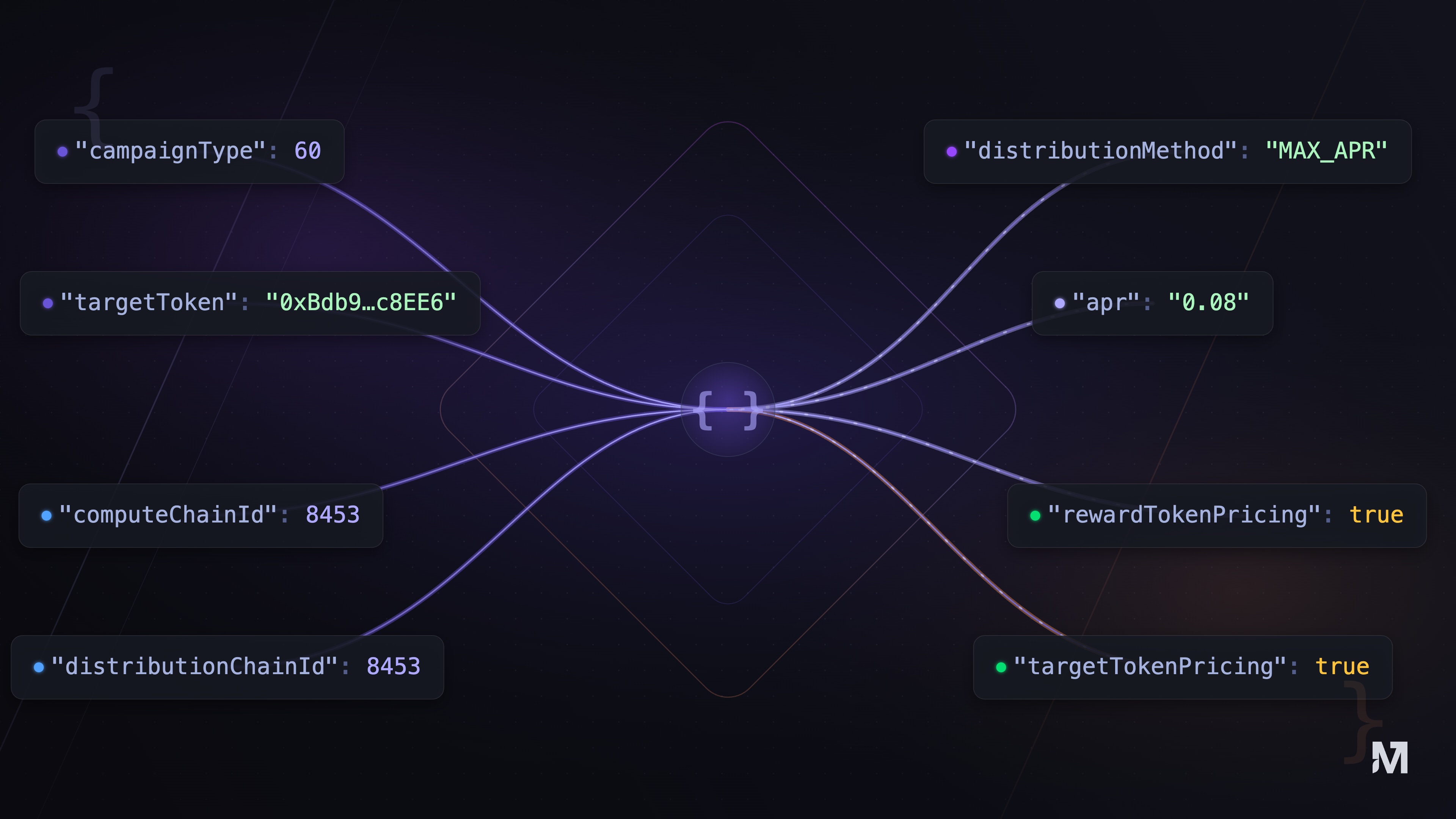
Put the common pieces together and a basic configuration is surprisingly compact. Here is a minimal one for a token-based campaign:
{
"campaignType": 60,
"targetToken": "0xBdb9300b7CDE636d9cD4AFF00f6F009fFBBc8EE6",
"computeChainId": 8453,
"distributionChainId": 8453,
"distributionMethodParameters": {
"distributionMethod": "MAX_APR",
"distributionSettings": {
"apr": "0.08",
"rewardTokenPricing": true,
"targetTokenPricing": true
}
}
}You can see both layers at work. The computeChainId and distributionChainId are standard fields, plain values that frame the campaign. The campaignType together with its targetToken is the campaign type structured input, and distributionMethodParameters is the distribution method structured input, each an object with its own settings. A full configuration also carries the remaining standard fields such as creator, rewardToken, amount, and the start and end timestamps.
You may notice that some of these values are plain numbers. Each campaign type has a numeric identifier in Merkl, and 60 is the one for a token-based (ERC20) campaign. The chain fields use chain IDs, the standard numbers that identify each network across the ecosystem, so 8453 is Base. Using identifiers like these lets a configuration point to a specific type or chain without ambiguity.
Read in plain language, this configuration rewards anyone holding Aave cBTC (the targetToken), with activity measured and rewards paid out on Base, and it spends the budget to keep that opportunity at an 8 percent APR (MAX_APR set to 0.08). No scoring overrides and no hooks. That is a complete, working campaign.
The schemas are the source of truth
You do not have to memorize any of this. Merkl publishes the exact structure of every input as machine-readable schemas, and they are the definitive reference for what each campaign type, method, and hook expects.
The schema explorer lets you browse every structured input and inspect the exact fields each one accepts. These schemas are read live from the public API, so they always reflect what is currently supported. If a field is in the schema, it works. If it is not there, it is not supported yet.
This matters because it means a configuration is never a guessing game. Whatever you can build, the schema describes it precisely.
Conclusion
The reason this model is worth understanding is that it scales. The same standard fields and structured inputs behind a simple single-token reward also power the most intricate programs on Merkl. There is no separate system for complex campaigns, just one configuration model where complexity is a matter of which inputs you reach for. That makes it a powerful way to read any campaign: once you see it as a set of standard fields and structured inputs, even the most advanced ones stop being a black box.
Related Guides

Keep custody of your tokens with token wrappers
Run Merkl campaigns without ever transferring your reward tokens — Merkl is just the distribution infrastructure, you stay in control of the funds
How to run incentive campaigns that actually work
Proven tips and recommendations based on our experience running the biggest and most successful incentive campaigns, from goal-setting and budget sizing to liquidity retention